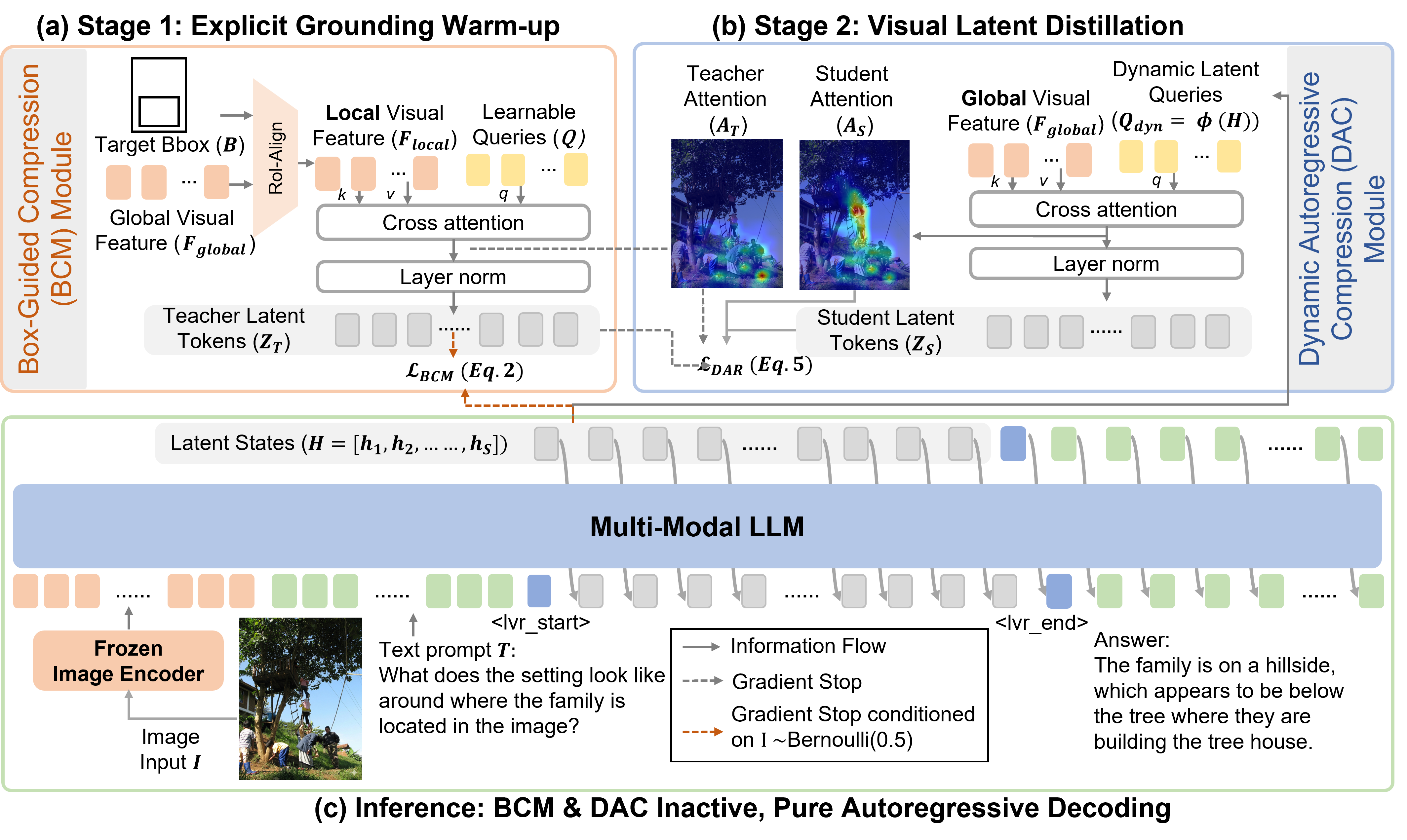
Transform MLLMs into
Active Interrogators.
V-Reflection introduces a "think-then-look" visual reflection mechanism where latent states act as dynamic probes that actively interrogate the visual feature space — grounding each reasoning step for task-critical evidence.
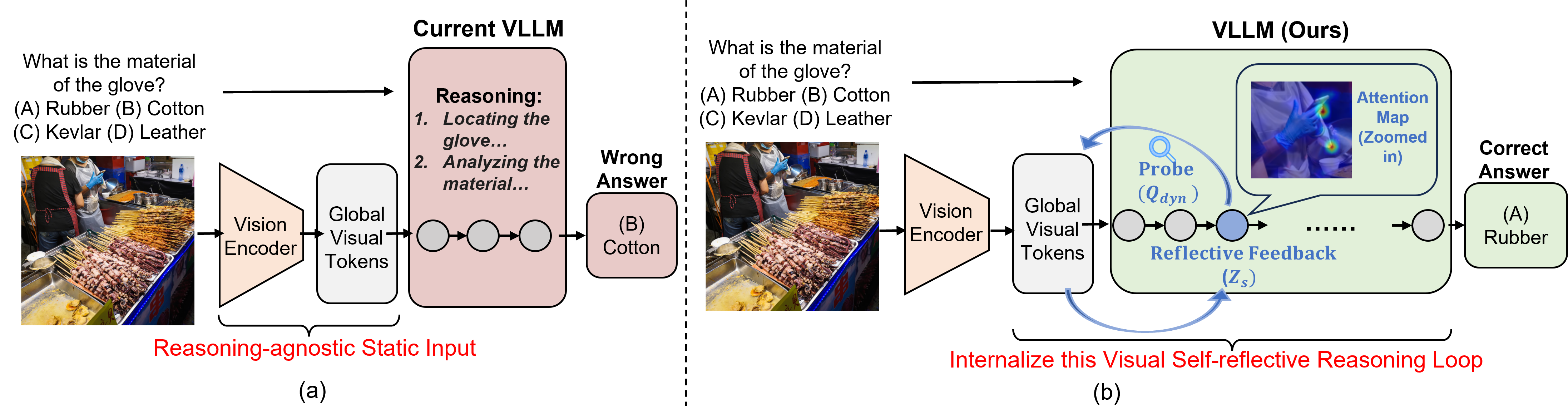
(a) Traditional MLLMs treat visual information as a static input, leading to perception hallucinations (e.g., "Kevlar") by prioritizing language priors over visual evidence. (b) V-Reflection's "think-then-look" mechanism uses evolving latent states as dynamic probes (Qdyn) to retrace global visual features, accurately localizing task-critical evidence (e.g., the rubber glove) for a precise answer.